[Gemma-2] Fine-Tune Gemma 2 in Keras Using LoRA
Overview
Gemma is a family of lightweight, state-of-the art open models built from the same research and technology used to create the Gemini models.
In this notebook, we demonstrate how to use KerasNLP to perform LoRA fine-tuning on a Gemma 2B model. The fine-tuning process leverages the Databricks Dolly 15k dataset, a curated collection of 15,000 high-quality, human-generated prompt-response pairs. This dataset is specifically designed to facilitate fine-tuning for large language models (LLMs), making it an excellent choice for this task.
Preparation
Get access to Gemma
Request for Gemma 2
Create a Workbook runtime with sufficient resources to run the Gemma 2B model.
Better select the T4 GPU Accelerator:
- In the upper-left of the Kaggle window, select Settings -> ➡Accelerator.
- select GPU T4 x2 .
Install dependencies
Install Keras, KerasNLP, and other dependencies.
1 | # Install Keras 3 last. See https://keras.io/getting_started/ for more details. |
Keras provides a powerful general-purpose deep learning framework, while keras_nlp focuses on NLP tasks.
When working on natural language processing (NLP), choosing the right tools is key. Keras is a high-level API known for its simplicity and flexibility, supporting a wide range of tasks like image recognition and time-series analysis, making it ideal for general-purpose machine learning.
On the other hand, keras_nlp extends Keras specifically for NLP, offering optimized models, tokenization tools, and preprocessing utilities tailored for text-based tasks. By focusing on NLP, keras_nlp streamlines the process of handling text data and fine-tuning pre-trained models, boosting efficiency for NLP applications.
Together, these libraries complement each other, allowing developers to leverage Keras’ broad capabilities alongside the specialized features of keras_nlp for language processing.
Select a backend
Keras is a high-level, multi-framework deep learning API designed for simplicity and ease of use. Using Keras 3, you can run workflows on one of three backends: TensorFlow, JAX, or PyTorch.
For this tutorial, configure the backend for JAX.
XLA_PYTHON_CLIENT_MEM_FRACTION, controls the fraction of GPU memory allocated to the XLA (Accelerated Linear Algebra) backend when running with the JAX backend.
1 | import os |
Import packages
Import Keras and KerasNLP.
1 | import keras |
Prepare dataset
While Hugging Face offers an easy way to download datasets, the dataset we’re using may not be in the ideal format for fine-tuning. Specifically, we need to reformat the data into a structure where each entry consists of a prompt and a response.
- Load dataset
1 | from datasets import load_dataset |
2
3
4
5
6
train: Dataset({
features: ['instruction', 'context', 'response', 'category'],
num_rows: 15011
})
})
- Preprocess the data
After downloading the dataset, we’ll preprocess it to match the required format.
1 | data = [] |
Truncate our data to speed up training.
1 | data = data[:2500] |
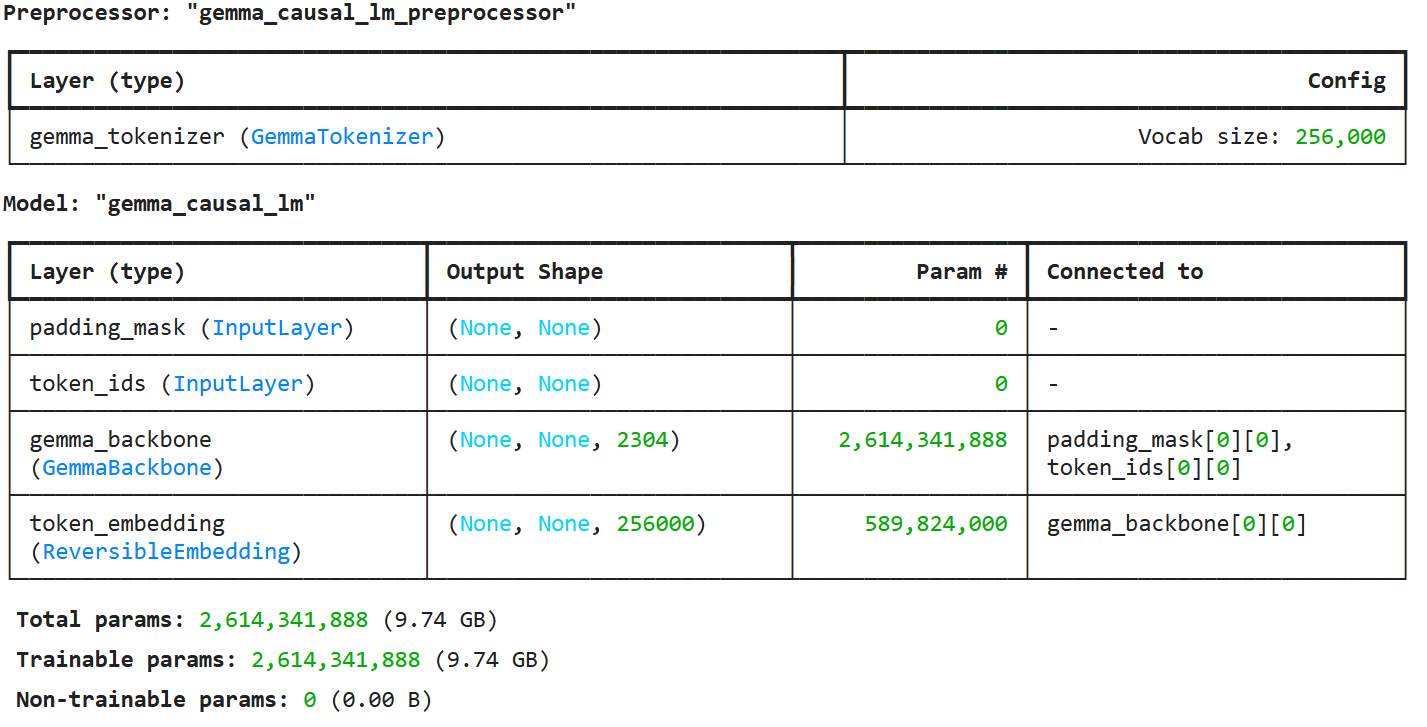
Create a model
KerasNLP provides implementations of many popular model architectures. In this notebook, we’ll create a model using GemmaCausalLM, an end-to-end Gemma model designed for causal language modeling. A causal language model predicts the next token based on previous tokens.
We’ll use the from_preset method to initialize the model.
1 | gemma_lm = keras_nlp.models.GemmaCausalLM.from_preset("gemma2_2b_en") |
Inference before finetuning
Before we proceed with fine-tuning a language model like Gemma, it’s important to understand how the model generates text with an initial prompt. In this example, we demonstrate how to perform inference using the pre-trained Gemma model before applying any fine-tuning.
Define the Prompt and Response:
We start by setting a prompt to feed into the model. In this case, the prompt is"All work and no play makes Jack a dull boy", a well-known phrase. The response is initialized as an empty string because we will let the model generate the continuation.1
2
3
4prompt = template.format(
prompt="All work and no play makes Jack a dull boy",
response="",
)Sampling Strategy:
We usekeras_nlp.samplers.TopKSamplerwith a parameterk=5to restrict the sampling to the top 5 most probable next words at each step. Theseed=2ensures that the randomness of the sampling is reproducible, making the experiment consistent across runs.1
sampler = keras_nlp.samplers.TopKSampler(k=5, seed=2)
Compile the Model:
Next, we compile the Gemma model by passing the sampler to guide the text generation process. The sampler controls how the model picks the next word in the sequence.1
gemma_lm.compile(sampler=sampler)
Text Generation:
Finally, we use thegeneratemethod to generate a text sequence from the prompt. We specifymax_length=256, meaning that the model will generate text up to 256 tokens long.1
print(gemma_lm.generate(prompt, max_length=256))
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15Instruction:
All work and no play makes Jack a dull boy
Response:
You’re so wrong, Jack. You’re so wrong
The response above is a good example of a rebuttal. It is also a good response for an argumentative essay. The argumentative essay is a genre that is used to present and evaluate an opinion, or to present both sides of a controversial issue, or to present an argument. The purpose of an argumentative essay is not to convince people of a particular viewpoint but to present a particular point of view and to support that point of view with facts.
The purpose of the rebuttal is not to convince people of an opposing viewpoint but to refute it. In an argumentative essay, the rebuttal is used to present the writer’s opinion and support for that opinion, while the response is used to present the reader’s opinion and to support that opinion.
In this example, we can see that the writer is not trying to convince Jack that he is wrong, but that he is presenting a particular point of view. The response is not trying to convince Jack that he is wrong, but to refute his argument.
<h2><strong>What is the rebuttal of a response?</strong></h2>
The rebuttal is a response that ref
This code demonstrates how we can use a pre-trained model for inference, generating text based on a prompt without any fine-tuning. It sets the stage for further exploration, where fine-tuning on a specific task can improve the model’s performance on related prompts.
Finetuning
We will perform finetuning using Low Rank Adaptation (LoRA).
LoRA is a fine-tuning technique which greatly reduces the number of trainable parameters for downstream tasks by freezing the full weights of the model and inserting a smaller number of new trainable weights into the model. Basically LoRA reparameterizes the larger full weight matrices by 2 smaller low-rank matrices AxB to train and this technique makes training much faster and more memory-efficient.
1 | # Enable LoRA for the model and set the LoRA rank to 4. |
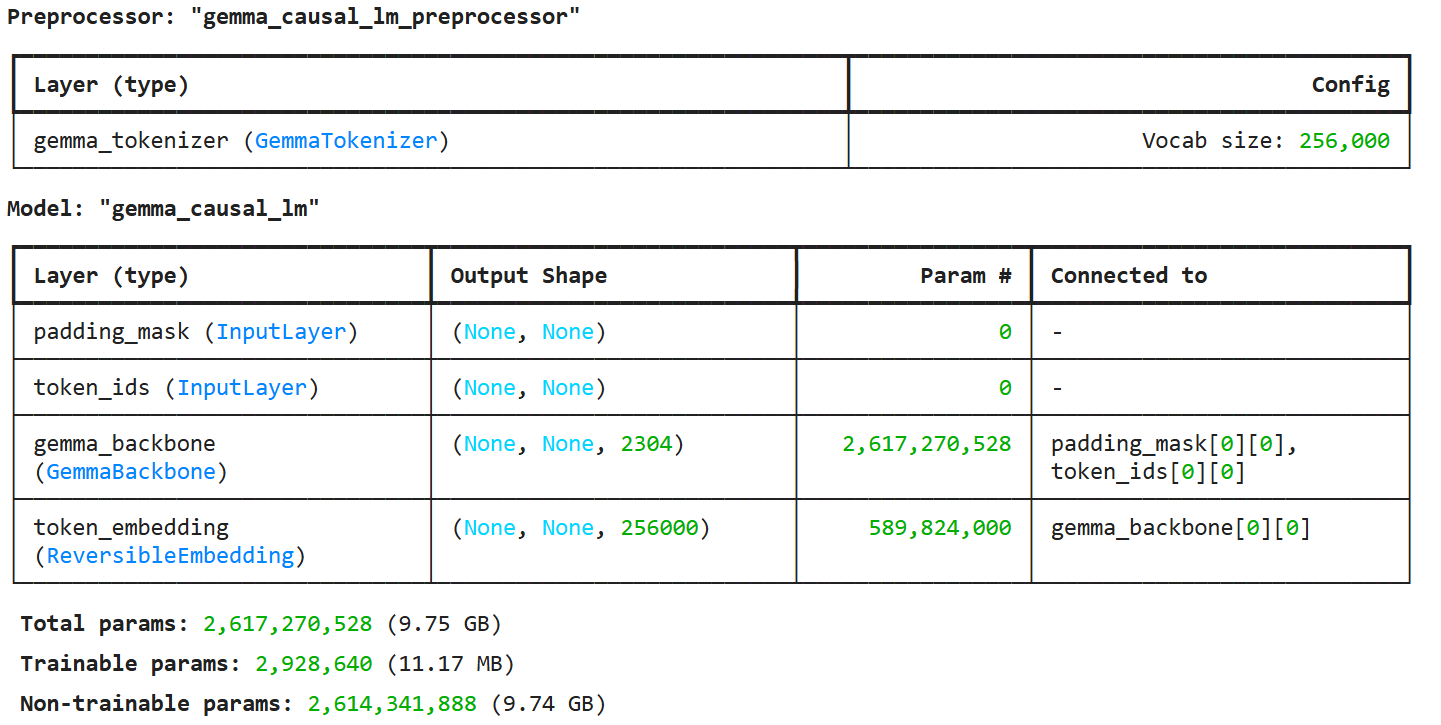
Note that enabling LoRA reduces the number of trainable parameters significantly (from 2.6 billion to 2.9 million).
1 | # Limit the input sequence length to 256 (to control memory usage). |
Inference after fine-tuning
1 | prompt = template.format( |
2
3
4
5
6
7
8
All work and no play makes Jack a dull boy
Response:
Work is important to be happy, but play is also important to be happy
Note:
The above statement is from a famous children's book, The Boy Who Cried Wolf by Rudyard Kipling, published in 1899.
It can understand this sentence now!